April 19, 2023
Many companies experience that their data foundation is becoming larger and more complex. More products, more channels, more services, and more customer segments to be served all increase the need for good data governance, and this is where the data organization comes into play.
As the need to work with an increasing amount of more complex data constantly arises, more companies are looking for ways to better utilize this data in value-creating contexts.
And here the concept of the “data organization” comes into play. The data organization is established to ensure that the company’s work with data creates value.
The data organization consists of one or more people who, through analysis, handling of large amounts of data, and the use of, for example, product data across digital platforms, manage to generate increased interest in the organization’s products, which ultimately leads to increased revenue.
An increased need for professionalism in data work
As we gain access to more data, and these data need to be published on an increasing number of channels, there is also a growing need for professional handling of data.
The development of a data organization can therefore also be seen as an ongoing process that never stops. The data organization is established to support the company’s needs, and scaling the data organization will often be a central strategic focus area that – if done correctly – delivers a high ROI on investments in data-related technologies and processes.
The effective data organization not only finds opportunities for automation and improvement of data processes but also entirely new ways to use data.
In this article we explore the concept of “data organization” by addressing the questions:
- What is a “data organization,” and why should you have one?
- Who makes up the data organization?
- What roles do the members of a data organization have?
- What does a successful implementation of a data organization in a company require?

What is a data organization, and why should you have one?
Most of the companies we work with daily, who experience an increase in the volume and complexity of their data, all share a desire to get better at using their data in value-creating contexts.
For these companies, processes and technologies that support the acquisition, enrichment, structuring, and publishing of data are central to the value creation taking place. With the PIM system as the focal point, product data is the raw material we and our clients focus on.
The most ambitious companies do not leave data work to chance (or random colleagues) but deliberately establish a so-called data organization.
The data organization ensures value creation through the use of data
This data organization is created to handle the work of turning raw data into a value-creating asset. This can be done by:
- ensuring correct access to data
- ensuring the possibility of easy data enrichment
- ensuring easy access to data (e.g., through well-structured APIs)
- and much, much more…
The size and structure of a data organization will always depend on the company’s size, the total amount of data (e.g., product data), and the company’s current and future technical setup.
Build a data organization by focusing on these basic requirements
If the development and implementation of a well-functioning data organization are to be secure and increase the chances of meeting the company’s goals, we find that there are several basic requirements that require continuous focus.
These basic requirements are fairly generic and will apply to all companies working with data. The basic requirements can be directly reformulated as functions or roles necessary for establishing and implementing a data organization, as well as the fundamental data processes owned by the data organization.
In the following sections, we will address these basic functions and suggest how to anchor them in the effective data organization.

Dataorganisation focus areas
Overall, the data organization is responsible for two distinct dimensions of working with the company’s data, which we have chosen to divide as follows:
- Dimension 1: “Inside-out” – the internal data the data organization is responsible for
- Dimension 2: “Outside-in” – the “endpoints” to which data ultimately must be distributed
Work on these dimensions naturally covers a range of activities that can be both technical and business-oriented.
“Inside-out” – the company’s data assets
The inside-out dimension focuses on the internal datasets necessary for operating the system landscape that constitutes the company’s operational backbone.
Here, we often encounter datasets for ERP, logistics, pricing, discount management, etc., which are found in virtually all trading companies today.
These datasets help make a product “sellable” and are the raw material the company can to a greater or lesser extent be skilled at refining.
“Outside-in” – the company’s customers, channels, and competitors
The outside-in dimension directs our focus towards customer behavior and the more usage-oriented needs found in the channels where a product is sold.
Here, we typically encounter datasets supporting search, comparison, navigation, user-generated data in various forms, copywriting, SEO optimization, etc.
These datasets help make the product “findable” and “buyable,” and are critical for a good user experience, which ultimately is the competitive parameter that leads to a sale.
Ideally, companies aiming for effective data organizations must ensure that both of these dimensions are managed.

Data organization roles and areas of responsibility
In practice, one of the discussions companies have with themselves when setting up a data organization is whether it makes sense to have “pure” full-time competencies within the data organization or not.
Regardless of whether the data organization consists of full-time or part-time competencies, or a mix thereof, the roles these competency profiles must fill are always roughly generic, so this discussion is rarely as significant for the data organization’s area of responsibility as it is for the company’s internal modus operandi and general operational planning.
Roles in the data organization
For most companies, it therefore applies that the effective data organization consists of the following roles (which typically focus on the inside-out dimension):
- Data owner
- Definition: A Data owner is a person who makes decisions such as:
- Who has the right to access data?
- Who is allowed to edit data?
- How (and where) may data be used?
- Data owners do not necessarily work with data every day but are responsible for monitoring and protecting one or more data domains (this can be, for example, ERP master data, supplier data, CRM data, images, and videos).
- Definition: A Data owner is a person who makes decisions such as:
- Analytical data expert (Data scientist)
- An analytical data expert is a role that:
- Has the technical skills to solve complex problems related to, for example, creation, structuring, or cleaning of data
- Has the curiosity to explore which problems should—and can—be solved.
- Analytical data experts are in their purest form partly mathematicians, partly computer scientists, and partly trendspotters (“business-oriented”).
- An analytical data expert is a role that:
- Data supporter (Data steward)
- The data supporter’s role is primarily to support the user community in the data-driven organization
- The data supporter is thus responsible for collecting, organizing, and evaluating data tasks and problems, after which they propose solutions to the organization.
- Data architect
- A “Data architect” is an IT professional responsible for defining the policies, procedures, models, and technologies used to collect, organize, store, and access corporate information
- Data architects focus on business intelligence relationships as well as high-level data policies.
- Data partner
- A data partner is an organization that delivers data and/or services according to the company’s “Master Data Agreement(s).”
As a supplement to these roles, there is a need for a function focusing on the outside-in perspective:
- Channel owner
- A Channel owner is responsible for ensuring the sales channel at all times supports all user needs of the channel’s users (customers) and effective purchase journeys.
- Content creators
- A content creator is typically an internal function that creates content for the channels where needed. Examples include copywriters and photographers.
It is important to emphasize that all these functions can very well be combined in one and the same person. This is usually the case in smaller companies early in their digital journey. In larger organizations, a young data organization will typically also reflect that one or a few people handle multiple roles.
Remember to review your roles and role descriptions
But as the company grows and scales, and more channels, data/products, and data domains emerge, focus should be on creating an organization where the functions are anchored in “pure” roles. Typically, the workload associated with handling individual responsibilities naturally pushes the data organization in this direction.

Implementation of a data organization – what does it require?
For the various role descriptions not to become just fancy titles hung around people’s necks in the organization, all our experience points to the fact that a good implementation of the core principles is crucial for your success.
In our view, the successful implementation of the data organization requires:
- A healthy system landscape and an associated toolbox, that supports the necessary data management for the various domains and functions described in the previous section
- Logical function and role descriptions, that make sense to the people within the organization
- Training and onboarding programs, ensuring that the individuals behind the functions have the necessary professional qualifications and the overall understanding needed to carry out the intended tasks
- Customized workflows and processes, which ensure efficient operations across the various functions and enable the organization to continuously manage and adapt.
A successful implementation therefore rests on insight and effort from the entire organization.
As with any good change process, management support is critical to the organization’s ability to handle the shared task. This applies both in terms of management’s allocation of resources and the energy and support that employees experience.
Key tools in successful implementation
Looking closer at the four points listed above, it is relevant to elaborate on their scope and impact more precisely:
Focus area #1 – system landscape and toolbox
We have already mapped out that these roles are necessary for good data governance and for a healthy data organization to function.
But what about your system landscape – does it also support the daily data work of the various functions?
Standardizing your tech stack helps get the data organization started
Over time, we have seen many examples of system landscapes where a mixing of data domains has led to the company carrying a large technical debt.
This typically arises because IT systems that were never intended to handle more than a single domain, for various reasons, have been made responsible for two, three, or more domains. A classic example is the ERP system, which has been extended with functionality and fields to handle channel data, or the DAM system, which is used to manage product data and pricing.
The result is always the same: expensive, complicated, and fragile “here-and-now” solutions to problems that fundamentally only continue to evolve. The consequence of poor investments is that companies end up with costly, static systems where all flexibility has been removed from the architecture.
Create a roadmap for your overall system landscape
If the domain mixing is too extensive, there is a risk that this becomes an obstacle to the efficiency of the data organization’s work. As a result, the company never achieves the real benefits that the data organization is capable of creating.
A healthy system landscape has a clearly defined architecture and a technical roadmap that paves the way for sustainable and forward-looking development of the company’s technical foundation.

Focus area #2 – Logical function descriptions
As mentioned, we consider the various functions to be generic and thus applicable to all companies that handle data.
The logical function descriptions map out the responsibilities of the roles and serve as a basis for dialogue about the daily operations of the data organization.
However, the exact function description should always be adapted to each individual company, as these usually become very specific when the existing system landscape is taken into account. Rarely are there two companies working with exactly the same systems in exactly the same architecture.
Analyze your workflows and identify optimization opportunities
Best practice is therefore that companies create customized function descriptions that fit the domain and system landscape in which the company operates.
For example, if a company offers a broad assortment of very different products or sells a mix of branded products purchased from a supplier or wholesaler together with a range of own-brand products, where it owns most of the data process, these function descriptions will be very specific.
Here, both the complexities of importing data from many sources and the enrichment and presentation of data must be taken into account to ensure that the correct brands are presented in the correct contexts so that there is no confusion about copyright, brand ownership, and any compliance issues.

Focus area #3 - Training and onboarding programs
Following the role descriptions in section 2, training and onboarding programs are tools to spread “best practices” regarding the specific execution of data work.
The educational and training materials are also a good place to retain knowledge so that it does not leave the company.
For some companies, there will be freedom regarding systems and methods, while the majority of companies enforce some kind of policy concerning which systems and methods each employee is expected to use.
Choose the training method that best fits your organization
Onboarding programs and training materials are not new concepts, and there are several well-known formats you can use:
- Printed materials
- Video training
- Peer coaching
- Course days
- Case training
- Virtual training
As far as we know, there is no silver bullet when it comes to choosing the “most suitable” training format.
For example, if you choose peer coaching, our recommendation is to base the training program on printed materials to ensure a consistent thread throughout the training.
If you hold internal course days (possibly with external instructors), it is important that the pace, tone, and content match the temperament of the participants—otherwise, you quickly waste valuable time and risk creating frustration within the team.
You can choose to make training and onboarding programs very specific and include details about concrete system features. This will usually result in easy onboarding but often leads to more administration in the form of maintaining the training materials each time a change is made to a system setup.

Focus area #4 - Workflows and processes
In data work, everything starts and ends with effective processes!
Whether you choose a monolithic-oriented approach to your IT architecture, where multiple functions are handled within/by the same platform, or you opt for a best-of-breed approach in a microservice architecture, there is a process that spans across the organization and system landscape [MIK: What is meant by this?].
Our clear recommendation is that you always start by focusing on what we call the “bare process.”
Think in process steps – not software-specific functions
The method behind the “bare process” model relies on excluding your systems/software from your analysis and instead focusing on the different process steps between the various functions in the data organization.
In short, you should not describe which buttons you press or what the naming of functions in the systems is. Instead, focus on the business function – "someone" must do "something" before "someone else" can do "something else." All of this happens until a condition is met and a benefit is realized.
By adopting this focus, you will gain clarity about the places where your processes and workflows work well and equally where they work poorly – or not at all. When processes don’t work, the term “[a] broken process” is often used, referring to processes that cause disproportionately large time waste. With the bare process method, we shed light on exactly what doesn’t work and how we can solve the problem.
The workflow analysis shows the way
PicoPublish has developed a workflow analysis format that provides full clarity on the state of your processes, reveals all errors, and assigns value to the potential of getting the process back on track.
A workflow analysis can typically be conducted in one or two days. Typically, the analysis is based on conversations with and observations of key employees in your data organization. By mapping all process steps, it becomes possible to gain an overview of how various hidden workflows and inefficiencies in task handoffs create opportunities for improvement.

Follow-up activities - Create the overview!
At this point in the process, we have come so far that we have identified and described the different functions in the data organization, we have also gained control of the system landscape and the most central processes in the company.
How then do you create an overview of the data organization’s functions in relation to the data that must be handled, and which gives us the frame of reference the organization works within daily?
There are different ways to do this. The very simple method is to set up a table containing the data and data owners that fall under the umbrella of the data organization.
The table should be set up based on a logic that makes sense internally. For example, it could be based on product categories, where the table might be designed as follows:
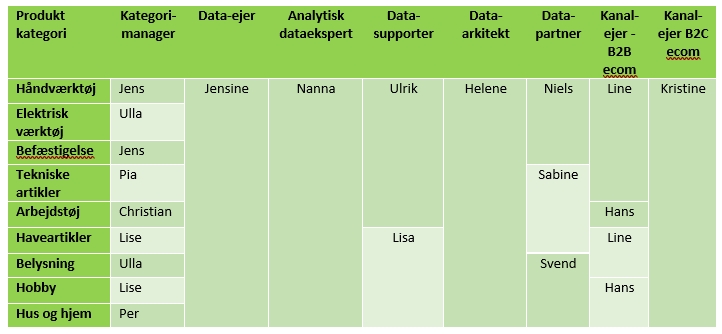
One thing is creating the overview. Another, however, is to operationalize the overview in a way that supports your overall goals. For many PIM systems, it is possible to set up dashboards and workflows that support automation of the processes involved in working with product data.
An example could be “Products without images,” which can be made visible through a dashboard. The products that meet these conditions — i.e., missing images — can then automatically be assigned to the appropriate responsible person’s task list in the system, so the employee can focus on enrichment, and NOT on identification and troubleshooting.
If this is thought through and implemented correctly, you will move from a simple overview to real process support with a high potential for automation of processes and task management.
Conclusion and checklist
Building data organizations takes time, and it can be difficult to do without external help. We are typically too entrenched in our own routines to see their (potentially harmful) effects.
In this post, we have outlined the model we use when helping companies build their internal data organizations. One of the recurring requests we hear from companies is the elimination of trivial tasks and/or slow, manual processes.
With a workflow analysis, it quickly becomes clear how the different roles within the data organization can relieve each other and how work can be fully or partially automated so that the entire data organization is eased. As with much other automation, the purpose is often to free up time for important core tasks among team members.
In conclusion, we will summarize the aspects we believe are essential to focus on when building an effective data organization.
For ease of use, we have created our summary as a checklist that you can use to assess where the greatest needs are in your company.
Checklist for building a strong data organization
